

Artificial intelligence has fundamentally altered software development workflows in 2026, progressing from autocomplete suggestions to autonomous agents that write production code, generate test suites, submit pull requests, and debug complex systems with minimal human intervention. This transition from AI-assisted coding to agentic coding represents the most significant productivity shift in software engineering since the introduction of integrated development environments in the 1990s. Development teams now function as orchestrators of AI capabilities rather than writing every function manually, fundamentally changing how organizations structure engineering teams and evaluate developer productivity.
Two platforms dominate the agentic coding landscape: Anthropic’s Claude Code and OpenAI’s Codex. While both systems generate code from natural language descriptions, their architectural approaches, integration patterns, and suitability for different organizational contexts differ substantially. According to Stack Overflow’s 2026 Developer Survey, 68% of professional developers now use AI coding assistants daily, with Claude Code and Codex representing 73% of reported AI tool usage among respondents. This widespread adoption creates urgency for engineering leadership to evaluate which platform aligns with team composition, project requirements, and development workflows.
The choice between Claude Code and Codex extends beyond feature comparison to encompass integration complexity, total cost of ownership, organizational learning curves, and alignment with existing development practices. Organizations selecting AI coding platforms based solely on benchmark performance or feature lists risk implementing tools that conflict with established workflows, introduce security vulnerabilities, or require substantial process changes that negate productivity gains. This analysis examines Claude Code and Codex through the lens of organizational context, providing decision frameworks for startups, agencies, SaaS teams, and enterprise engineering organizations evaluating AI coding adoption in 2026.

Understanding Agentic Coding: Beyond Autocomplete
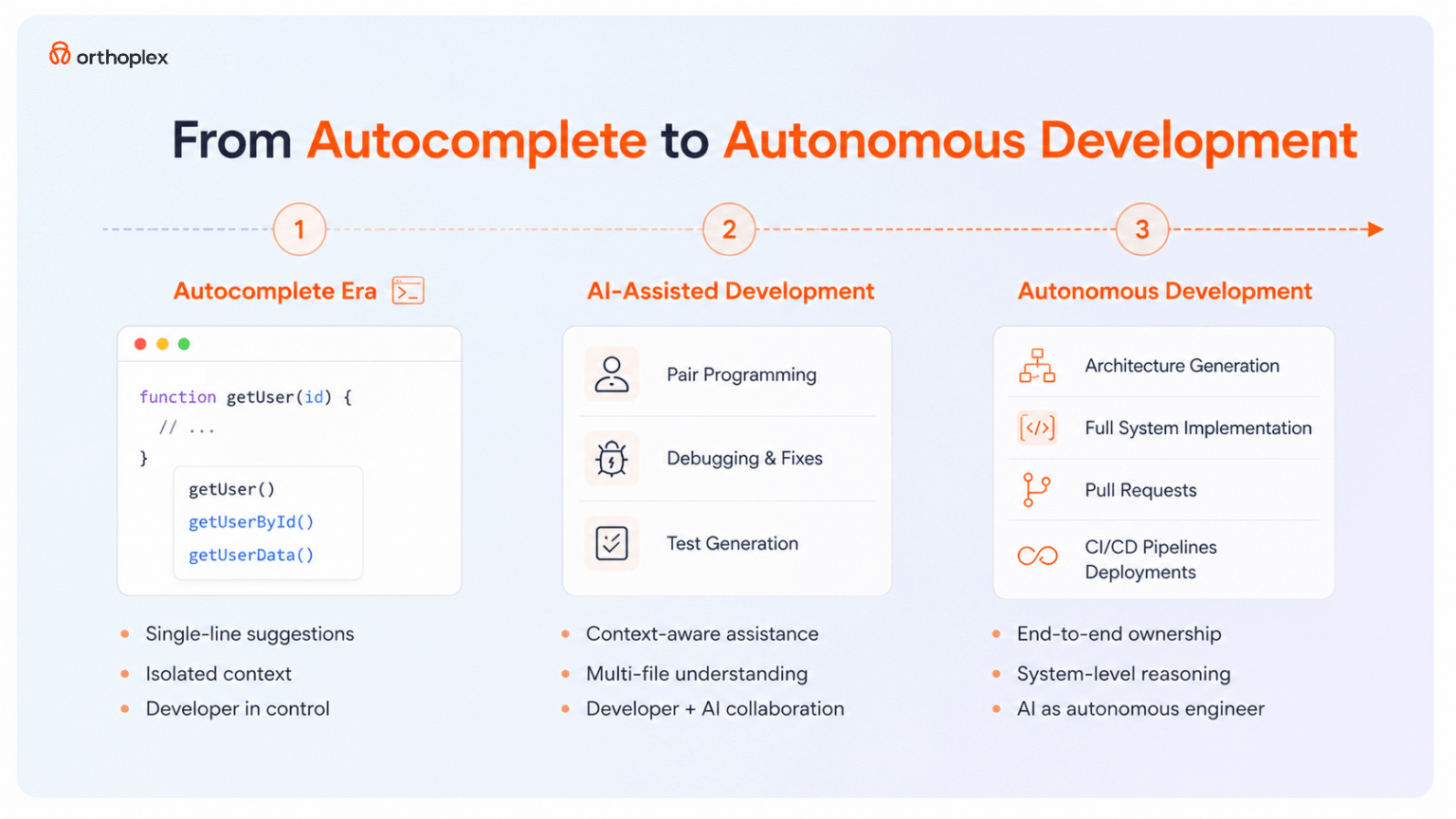
Traditional code completion tools including GitHub Copilot, TabNine, and early Codex implementations provided context-aware suggestions that accelerated typing but required developers to maintain cognitive ownership of architecture, logic flow, and implementation details. These autocomplete systems operated within the active file, offering single-line or small block suggestions based on surrounding code context and learned patterns from training data. Developers retained responsibility for overall system design, error handling, edge cases, and integration between components.
Agentic coding tools represent architectural evolution where AI systems assume responsibility for complete feature implementation from natural language specifications. Rather than suggesting the next line of code, agentic systems analyze requirements, design appropriate data structures, implement business logic, generate comprehensive test coverage, and create pull requests with detailed explanations of implementation decisions. This autonomy shift requires different evaluation criteria focused on architectural coherence, code quality consistency, and alignment with organizational standards rather than keystroke reduction metrics relevant to autocomplete tools.
According to Anthropic’s Sate of AI Development Report, engineering teams using agentic coding tools reported 40% reduction in time-to-implementation for well-specified features, with productivity gains concentrated in boilerplate code generation, test suite creation, and documentation writing. However, the same research identified that poorly specified requirements or ambiguous acceptance criteria resulted in wasted effort debugging AI-generated code that misunderstood intent, emphasizing the importance of clear requirement specification in agentic workflows.
The transition to agentic coding requires organizational process changes beyond tool adoption. Development teams must establish patterns for requirement specification that AI agents parse effectively, implement code review processes accounting for AI-generated implementations, and develop testing strategies that validate AI output meets functional and non-functional requirements. Organizations treating agentic coding tools as drop- in replacements for human developers without workflow adaptation encounter quality issues, technical debt accumulation, and team frustration that undermines potential productivity benefits.
Claude Code: Architecture and Capabilities
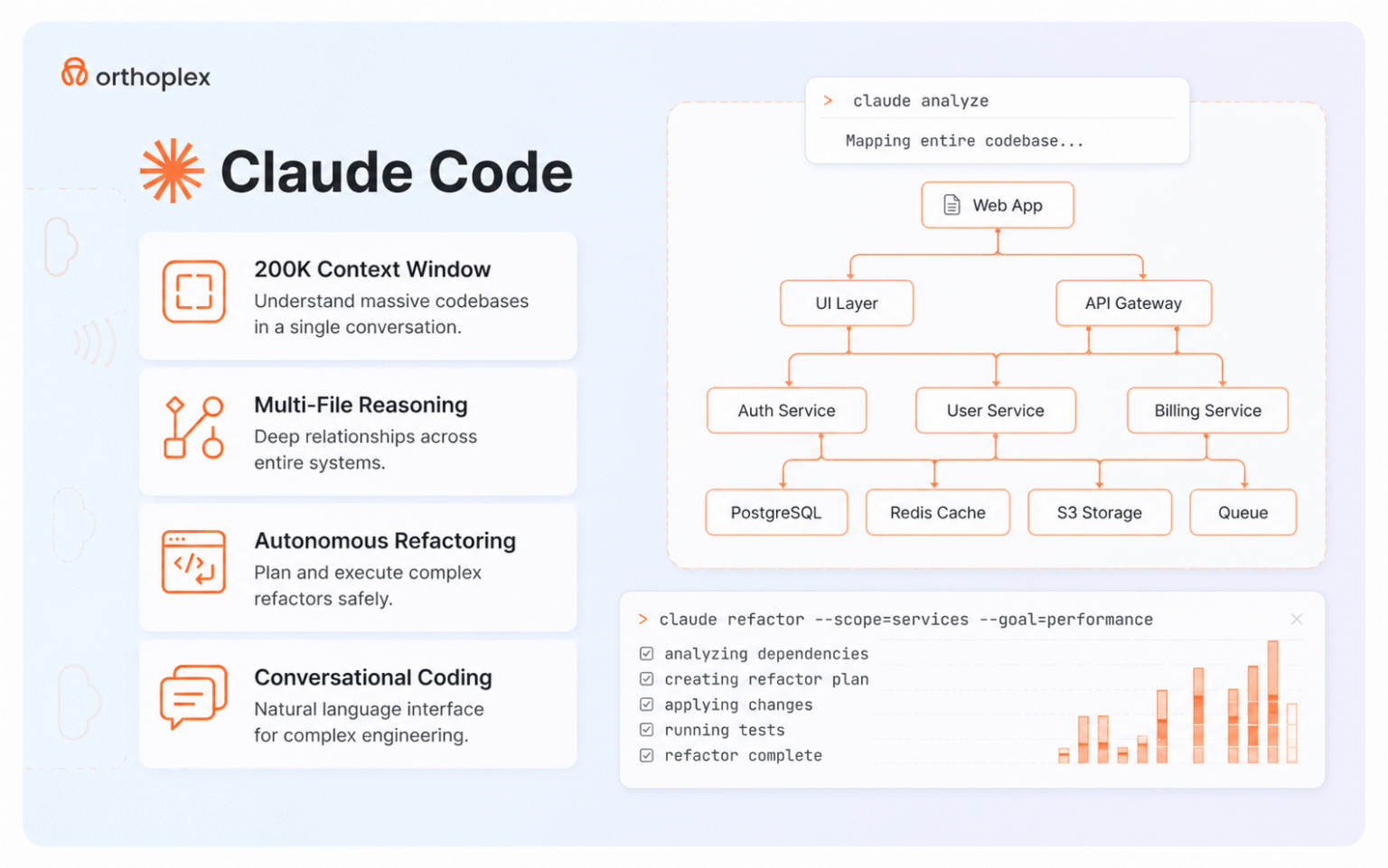
Claude Code operates as a command-line interface that integrates with existing development environments, version control systems, and CI/CD pipelines through terminal-based interactions. The tool maintains conversation context across multiple interactions, allowing developers to iteratively refine implementations through natural language feedback rather than manual code editing. This conversational approach aligns with how senior developers collaborate with junior team members, making the interaction model familiar to experienced engineers accustomed to code review and pair programming workflows.
The underlying language model powering Claude Code—Claude Sonnet 4.5 as of May 2026—demonstrates particular strength in understanding complex system architectures, maintaining consistency across large codebases, and generating code that adheres to established patterns within the target repository. According to benchmark published by Anthropic, Claude Code achieves 89% correctness on the HumanEval benchmark and 85% on the APPS coding challenge, with notably higher performance on tasks requiring multi-file modifications and system-level reasoning compared to isolated function implementations.
Claude Code’s context window of 200,000 tokens enables analysis of substantial codebases, including multiple related files, documentation, and historical implementation patterns. This extended context allows the system to maintain architectural consistency when implementing features across frontend components, backend APIs, database schemas, and infrastructure configurations. Development teams report particular value in Claude Code’s ability to understand existing patterns and replicate them in new implementations, reducing the inconsistency common when multiple developers implement similar features using different approaches.
File system access and modication capabilities allow Claude Code to operate autonomously within project directories, creating new les, modifying existing implementations, and organizing code according to project structure conventions. The tool integrates with Git, automatically creating branches, committing changes with descriptive messages, and generating pull request descriptions that explain implementation decisions and testing considerations. This automation reduces context switching between coding tasks and version control operations, maintaining developer ow state during feature implementation.
Claude Code implements safety mechanisms including change conrmation prompts before le modications, di display showing proposed changes before application, and rollback capabilities through Git integration. These guardrails prevent unintended code deletion or modication while maintaining development velocity, addressing concerns about autonomous AI agents making destructive changes to production codebases. Organizations can congure safety levels balancing autonomy against risk tolerance, with stricter controls appropriate for production environments and more permissive settings accelerating prototyping workows.
Codex: Integration and Ecosystem
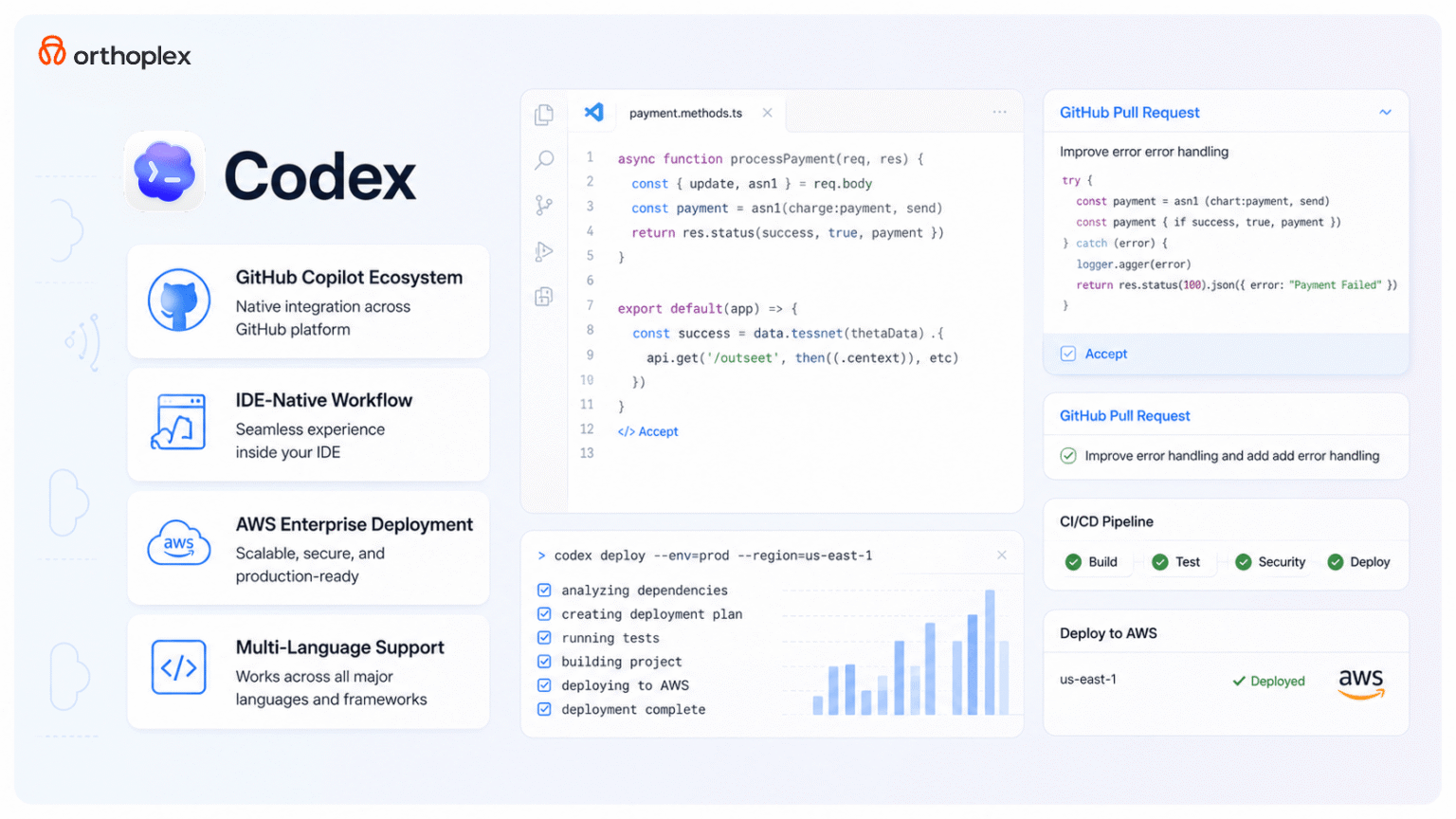
OpenAI’s Codex powers multiple development tools including GitHub Copilot, but standalone Codex API access enables custom integrations tailored to organizational workows and toolchains. The Codex API accepts natural language descriptions or code comments and returns code implementations in numerous programming languages, with particular strength in Python, JavaScript, TypeScript, and Go. Unlike Claude Code’s conversational interface, Codex operates primarily through single-turn interactions where developers provide complete specications and receive generated implementations.
Codex’s integration with GitHub through Copilot provides seamless in-editor experience within Visual Studio Code, JetBrains IDEs, Neovim, and other development environments supporting the Language Server Protocol. This integration model reduces context switching compared to terminal-based tools, allowing developers to remain within familiar editing environments while accessing AI capabilities through keyboard shortcuts and inline suggestions. According to GitHub productivity research, developers using GitHub Copilot complete tasks 55% faster than those without AI assistance, with accuracy remaining consistent between AI-assisted and manual implementations after code review.
AWS integration announced in early 2026 enables Codex deployment within enterprise cloud environments, addressing data sovereignty and security requirements that prevented adoption by organizations with restrictions on transmitting proprietary code to external APIs. This deployment model allows enterprises to fine-tune Codex on internal codebases, improving suggestion relevance and adherence to organization-specfic patterns while maintaining control over training data and model weights. The AWS integration represents OpenAI’s acknowledgment that enterprise adoption requires exibility beyond public API access.
Codex supports multiple interaction modes including completion (generating code following a prompt), insertion (filling gaps within existing code), and editing (modifying existing implementations based on instructions). These modes provide exibility for different development scenarios, with completion appropriate for new feature implementation, insertion valuable for adding functionality to existing code, and editing enabling refactoring and optimization tasks. Developers select interaction modes based on task characteristics, though this flexibility introduces learning curve compared to Claude Code’s unied conversational interface.
Fine-tuning capabilities allow organizations to specialize Codex for domain-specfic languages, internal frameworks, or coding standards unique to the organization. The fine-tuning process requires labeled datasets of code examples demonstrating desired patterns, with training costs and duration scaling with dataset size and model complexity. Organizations with substantial proprietary frameworks or domain-specic requirements realize value from fine-tuning, while those primarily using standard languages and frameworks find pre-trained Codex adequate for most development tasks.
Claude Code for Startups: Speed and Iteration
Startup engineering teams prioritize implementation velocity and iteration speed over comprehensive testing and documentation, operating under resource constraints that prevent large engineering teams and extensive code review processes. Claude Code’s conversational interface and autonomous feature implementation align well with startup development patterns where requirements evolve rapidly and technical debt is acceptable tradeoff for market validation speed.
The ability to specify features in natural language and receive complete implementations including basic tests reduces time from concept to functional prototype. Startup founders without deep technical expertise can articulate product requirements to Claude Code and receive working implementations suitable for customer demos and early user testing. This accessibility democratizes product development, allowing non-technical founders to maintain development momentum during pre-funding periods when hiring experienced engineers is financially prohibitive.
Claude Code’s extended context window proves particularly valuable for startups where architectural decisions remain uid and substantial refactoring occurs frequently as product direction evolves. The system maintains coherence across changes, updating dependent components when core data structures or API interfaces change. This automatic propagation of architectural changes reduces the manual coordination typically required when refactoring early-stage codebases, allowing small teams to move faster without accumulating inconsistencies that complicate future development.
Cost considerations favor Claude Code for resource-constrained startups. As of May 2026, Claude Code pricing operates on per-requests basis a tied to token consumption, with typical feature implementations costing $0.15-$0.45 depending on complexity and context requirements. This usage-based pricing allows startups to scale AI coding expenses with development activity, avoiding xed subscription costs that burden early-stage budgets. Compared to hiring additional engineers at $120,000-$180,000 annual salaries, even extensive Claude Code usage represents minimal expense while providing productivity multipliers for existing team members.
However, startups must implement discipline around requirement specication and code review despite velocity pressures. Deploying AI-generated code directly to production without human review introduces bugs, security vulnerabilities, and architectural decisions that create technical debt requiring expensive remediation. Successful startup implementations establish lightweight review processes where senior engineers validate AIgenerated code for security issues and architectural alignment before merging, balancing velocity against quality.
Integration with startup-friendly tools including Vercel, Supabase, and serverless platforms proves straightforward, as Claude Code generates implementations using these platforms’ conventions and best practices. Startups building on modern infrastructure-as-code platforms and API-first services find Claude Code produces deployment-ready code with minimal modication, accelerating the path from development to production deployment.
Codex for Development Agencies: Client Diversity and Standardization
Development agencies manage multiple concurrent client projects across diverse technology stacks, industries, and requirement specications. This portfolio diversity creates challenges for AI coding tool adoption, as systems optimized for specfic languages or frameworks may provide minimal value across the agency’s full project portfolio. Codex’s broad language support and GitHub Copilot integration provide exibility appropriate for agencies working across React, Vue, Angular, Python, Ruby, PHP, and other technology ecosystems.
Codex’s in-editor integration through GitHub Copilot maintains developer productivity across project context switches common in agency environments where engineers allocate time across multiple client engagements weekly. The consistent interface regardless of project technology stack reduces cognitive overhead compared to project-specic tooling, allowing developers to leverage AI assistance uniformly across their workload.
According to agency productivity benchmarks, developers using consistent AI tooling across projects report 30% less context-switching overhead than those adapting to project-specic tools.
Code standardization benefits agencies managing long-term client relationships where multiple developers contribute to projects over extended timelines. Codex-generated implementations tend toward idiomatic patterns for the target language and framework, reducing the style inconsistencies that accumulate when numerous developers with dierent preferences contribute to codebases. This standardization simplies code review, accelerates onboarding of new developers to existing projects, and reduces maintenance burden for long-term support engagements.
Client billing models inuence AI coding tool selection for agencies. Fixed-price projects benet from productivity tools that reduce implementation time, allowing agencies to maintain protability while delivering contracted scope. Time-and-materials engagements where clients pay for developer hours create misaligned incentives where productivity tools reduce billable time, though agencies increasingly nd clients value faster delivery over maximizing billable hours. Forward-thinking agencies position AI coding capabilities as client benefits enabling faster iterations and reduced project costs rather than internal cost reduction mechanisms.
GitHub integration provides client collaboration benets beyond developer productivity. Clients with technical teams reviewing agency deliverables often maintain GitHub presence for issue tracking and code review. Codexgenerated code appearing in pull requests with clear commit messages and implementation explanations facilitates client review processes, reducing the explanation burden on agency developers and improving client confidence in delivered implementations. This transparency becomes particularly valuable for agencies with clients performing acceptance testing and security reviews before deployment.
Agencies must establish governance frameworks for AI-generated code to prevent client IP concerns and maintain code quality standards. Clear policies regarding when AI assistance is appropriate, what review processes apply to AI-generated implementations, and how AI usage is disclosed to clients prevent misunderstandings and maintain professional standards. Some agencies nd clients specically request or prohibit AI tool usage based on internal policies, requiring exibility in development approaches across engagements.
Claude Code vs Codex for SaaS Development Teams
Software-as-a-Service development teams require sustained productivity across feature development, bug fixes, technical debt remediation, and platform scaling initiatives. The choice between Claude Code and Codex for SaaS teams depends heavily on existing development workows, team technical prociency, and the balance between new feature development and maintenance of established codebases.
Claude Code’s conversational interface excels for SaaS teams implementing substantial new features requiring multiple le modications and architectural decisions. The ability to iterate on implementations through natural language feedback proves valuable when building complex features with evolving requirements or when initial specications prove incomplete during development. SaaS product teams working closely with engineering can collaborate with Claude Code to rene implementations based on product feedback without engineers manually translating every requirement adjustment into code changes.
Technical debt remediation represents a common SaaS maintenance requirement where Claude Code provides particular value. The extended context window enables analysis of legacy code sections, identication of inconsistencies or anti-patterns, and generation of refactored implementations maintaining functional equivalence while improving code quality. SaaS teams allocate Claude Code to technical debt initiatives, allowing senior engineers to focus on architectural decisions while AI handles mechanical refactoring tasks.
Codex integration with existing IDE workows proves advantageous for SaaS teams with established development processes and code review practices. Developers remain in familiar environments while accessing AI assistance through keyboard shortcuts, reducing the process disruption inherent in adopting new tools.
Teams with strict code review requirements and comprehensive testing find Codex’s suggestion model preferable to Claude Code’s autonomous implementation, as developers maintain fine-grained control over what code enters the codebase.
Database schema migrations, API versioning, and backwards compatibility requirements common in SaaS development benet from Claude Code’s ability to understand system-wide implications of changes. When implementing breaking changes requiring coordinated updates across API endpoints, frontend components, and database schemas, Claude Code maintains consistency across modications that developers implementing changes manually sometimes overlook. This coherence reduces the post-deployment bugs common when complex migrations miss edge cases or fail to update all affected components.
Performance optimization represents another domain where AI coding tools provide value to SaaS teams. Claude Code can analyze performance bottlenecks, suggest optimizations, and implement caching strategies, database query improvements, or algorithmic enhancements. However, validation of AI-suggested optimizations requires careful benchmarking, as not all algorithmically superior approaches yield performance improvements in production environments with real data distributions and system constraints.
SaaS teams operating CI/CD piplines find both tools integrate eectively with automated testing and deployment workows. AI-generated code passes through the same test suites, linting rules, and security scans as human-written implementations, ensuring quality standards remain consistent regardless of code origin.
Teams with comprehensive test coverage benet most from AI coding tools, as tests provide validation mechanisms catching AI mistakes before production deployment.
Cost analysis for SaaS teams requires comparing AI tool expenses against engineering salary costs and productivity impacts. A SaaS team with 10 engineers at average compensation of $150,000 represents $1.5M in annual personnel costs. If AI coding tools increase productivity by 25% (conservative estimate based on published benchmarks), the effective capacity gain equals 2.5 engineers or $375,000 in annual value. Both Claude Code and Codex pricing remain well below this value threshold, making them economically attractive for SaaS teams of any size.
Codex for Enterprise Engineering: Scale and Governance
Enterprise engineering organizations prioritize governance, security, compliance, and standardization over development velocity. The regulatory requirements, security frameworks, and architectural standards common in enterprise environments create constraints that AI coding tools must accommodate without introducing compliance risks or security vulnerabilities. Codex’s AWS deployment model and ne-tuning capabilities address enterprise requirements that public API access cannot satisfy.
Data sovereignty concerns prevent many enterprises from transmitting proprietary code to external APIs for processing, regardless of vendor security guarantees or contractual protections. Codex deployment on AWS within enterprise cloud environments keeps code and model weights under organizational control, satisfying data classication policies and regulatory requirements prohibiting external data transmission. This deployment model proves essential for nancial services, healthcare, government, and defense contractors with strict data handling requirements.
Fine-tuning Codex on internal codebases enables adherence to organization-specfic patterns, internal frameworks, and architectural standards that generic models trained on public GitHub repositories cannot learn. Enterprises with substantial proprietary frameworks or domain-specic languages realize signicant value from fine tuned models that generate implementations consistent with internal conventions, reducing code review burden and improving AI suggestion acceptance rates. The ne-tuning process requires data engineering expertise and computational resources, but large enterprises typically possess these capabilities through existing machine learning teams.
Integration with enterprise identity management systems including Active Directory, Okta, and Ping Identityensures AI coding tool access aligns with organizational access controls and audit requirements. Codex enterprise deployments support SAML and OAuth authentication ows, enabling single sign-on experiences and centralized access management consistent with enterprise security standards. Activity logging and audit trails satisfy compliance requirements for tracking code generation activities, particularly relevant for regulated industries with software development lifecycle documentation obligations.
Code review automation represents an enterprise use case where Codex provides value beyond code generation. Enterprises can deploy Codex to analyze pull requests, identify potential issues including security vulnerabilities, performance concerns, or deviation from architectural standards, and generate review comments guiding developers toward compliant implementations. This automated review augments human reviewers, improving review coverage and consistency while reducing senior engineer time spent on mechanical review tasks.
Legacy system modernization projects benet from Codex’s ability to understand outdated languages and frameworks, generating modern equivalent implementations from COBOL, Fortran, or legacy Java codebases. Enterprises with substantial technical debt accumulated over decades can accelerate modernization initiatives by using Codex to translate legacy implementations into contemporary languages and frameworks, reducing the manual effort required for large-scale migrations that often extend across years and cost millions of dollars.
Enterprise procurement processes, vendor security assessments, and contract negotiations favor established vendors with enterprise sales teams and reference customers in similar industries. OpenAI’s enterprise sales organization and AWS partnership provide the procurement infrastructure enterprises require, including master service agreements, business associate agreements for HIPAA compliance, and security questionnaire responses. These administrative capabilities, while irrelevant to tool technical capabilities, often determine enterprise vendor selection in practice.
Technical Comparison: Performance and Accuracy
Objective performance comparison between Claude Code and Codex requires standardized benchmarks measuring code correctness, eciency, and adherence to best practices across programming languages and problem domains. Multiple benchmark suites provide different perspectives on AI coding capability, with no single metric fully capturing real-world development performance across the diverse scenarios developers encounter.
The HumanEval benchmark measures function-level code generation accuracy using hand-written test suites. As of May 2026, Claude Sonnet 4.5 powering Claude Code achieves 89% pass rate on HumanEval, while Codex scores 85%. This 4-percentage-point dierence represents measurable but modest advantage, with both systems performing substantially better than the 48% pass rate achieved by GPT-3.5 in 2023. For context, human expert programmers achieve 95-98% on HumanEval, indicating both AI systems approach but have not exceeded human performance on this benchmark.
The APPS benchmark evaluates more complex algorithmic problem-solving requiring multiple functions and data structures. Claude Code achieves 85% correctness on introductory-level problems, 72% on interview-level problems, and 54% on competition-level problems. Codex performance measures 82%, 68%, and 49% respectively across these diculty tiers. Both systems demonstrate degrading performance as problem complexity increases, with the gap between AI and human performance widening for the most challenging problems requiring creative algorithmic insights.
Multi-file coherence benchmarks measure AI coding agents’ ability to maintain consistency across related files, implement features spanning frontend and backend components, and respect architectural boundaries in modular systems. These benchmarks, while less standardized than single-function tests, provide insight into real world development scenarios where most features involve coordinated changes across multiple components. Internal benchmarks conducted by engineering teams at Anthropic indicate Claude Code maintains architectural coherence across 6-8 related les, while Codex implementations sometimes introduce inconsistencies when modications span more than 4-5 files.
Code quality metrics including cyclomatic complexity, code duplication, and adherence to language-specfic style guides show minimal difference between Claude Code and Codex outputs. Both systems generate relatively clean implementations that pass standard linting tools and maintain complexity metrics comparable to human-written code. Neither system demonstrates consistent advantage in code quality, suggesting training approaches and model architectures have converged on similar code generation patterns.
Security vulnerability introduction rates require careful measurement, as AI-generated code potentially contains common vulnerabilities including SQL injection, cross-site scripting, or insecure cryptographic implementations.
Analysis by security research teams indicates both Claude Code and Codex generate vulnerable code at rates between 12-18% depending on the vulnerability category, comparable to inexperienced human developers but substantially higher than security-conscious senior engineers. This vulnerability rate necessitates security review of AI-generated implementations, particularly for authentication, authorization, data validation, and cryptographic operations.
Security Implications and Code Review Requirements
AI-generated code introduces security considerations extending beyond traditional code review processes, as models trained on public code repositories potentially reproduce vulnerabilities present in training data without understanding security implications. Development teams implementing AI coding tools must establish review processes accounting for these risks while maintaining productivity benets that justify tool adoption.
Static analysis tools including SonarQube, Synk, and Semgrep provide automated vulnerability detection complementing human code review. These tools identify common vulnerability patterns including SQL injection, command injection, path traversal, and insecure deserialization that AI systems sometimes generate when implementing features involving user input processing or file system operations. Integrating static analysis into CI/CD pipelines prevents vulnerable AI-generated code from reaching production environments regardless of human review oversights.
Dependency management represents another security concern, as AI coding tools may suggest outdated packages with known vulnerabilities or introduce unnecessary dependencies increasing attack surface. Tools like Dependabot and Renovate automate dependency updates, but initial package selection requires human judgment ensuring AI-suggested dependencies align with organizational security policies and licensing requirements.
Secrets management in AI-generated code requires particular attention, as models occasionally generate example code including API keys, database credentials, or cryptographic keys that developers must remove before committing. Secret scanning tools including GitGuardian and TruffleHog detect committed secrets, but prevention requires education on proper secret management patterns and code review focused specically on credential handling in AI-generated implementations.
Authentication and authorization logic represents high-risk code where AI assistance requires enhanced scrutiny. Both Claude Code and Codex generate plausible-looking authentication implementations that may contain subtle vulnerabilities including timing attacks, insucient entropy in token generation, or authorization bypass conditions. Security-critical code benets from manual implementation by experienced security engineers or extensive review by security teams rather than accepting AI-generated implementations with cursory review
HIPAA compliance and other regulatory frameworks require documented development processes and code review evidence. Organizations using AI coding tools in regulated environments must establish policies determining what review processes apply to AI-generated code, what documentation satises audit engineering teams at Anthropic requirements, and how AI tool usage is disclosed in system security documentation. Some regulatory frameworks may require specic review processes for AI-generated code exceeding standard code review, creating additional overhead organizations must account for when evaluating AI tool ROI.
Integration with Development Workows and Toolchains
Effective AI coding tool adoption requires integration with existing development workows including version control, issue tracking, CI/CD pipelines, and documentation systems. The integration complexity and workow disruption associated with tool adoption often determines success or failure regardless of underlying AI capabilities.
Claude Code’s command-line interface integrates naturally with terminal-based development workows common among backend engineers and infrastructure teams. Developers accustomed to Git command-line operations, terminal-based editors, and shell scripting find Claude Code’s interaction model familiar and minimally disruptive. However, frontend developers and those preferring graphical IDEs may nd terminalbased interactions awkward compared to their established workows.
GitHub Copilot’s in-editor integration provides seamless experience for developers using Visual Studio Code, the dominant IDE with approximately 73% market share among professional developers in 2026. The integration appears as inline suggestions and chat interfaces within the familiar editing environment, reducing context switching and maintaining developer flow state. Support for JetBrains IDEs, Neovim, and other environments ensures broad compatibility across the developer tool ecosystem.
Issue tracking integration allows AI coding tools to implement features directly from ticket specications in Jira, Linear, or GitHub Issues. Claude Code can read issue descriptions, implementation requirements, and acceptance criteria, then generate implementations addressing specied requirements. This integration reduces manual copying of requirements into AI prompts and ensures traceability between issues and implementations for project management and audit purposes.
CI/CD pipeline integration subjects AI-generated code to the same automated testing, security scanning, and deployment processes as human-written code. Both Claude Code and Codex integrate effectively with GitHub Actions, GitLab CI, Jenkins, and other pipeline automation tools, as the generated code passes through standard Git workows where CI/CD hooks trigger. Organizations with comprehensive pipeline automation realize AI coding benefits without compromising quality gates or deployment processes.
Documentation generation represents a valuable secondary capability where AI coding tools excel. Both Claude Code and Codex can generate code comments, API documentation, and README les explaining implementation decisions and usage patterns. This documentation generation addresses a common developer pain point where documentation lags behind code changes, creating information asymmetry that complicates onboarding and maintenance.
Cost Analysis and Return on Investment
Financial evaluation of AI coding tools requires comparing subscription or usage costs against productivity improvements, opportunity costs of delayed features, and the alternative cost of hiring additional engineers. The calculation diers substantially across organizational contexts based on team size, average engineer compensation, and project types.
Claude Code pricing operates on usage-based model tied to API token consumption, with costs varying based on context size and response length. Typical feature implementations cost between $0.15-$0.45 per request, with complex features requiring iterative renement potentially reaching $1-$2 in aggregate API costs. For a development team generating 50 feature implementations monthly, Claude Code costs approximate $75-$100 per month—negligible compared to engineer salaries but requiring usage monitoring to prevent unexpected cost accumulation from inefficient prompt patterns.
GitHub Copilot pricing for business and enterprise tiers ranges from $19-$39 per user per month depending on seat count and annual commitment. For a 10-person development team, annual Copilot costs reach $2,280-$4,680, representing modest expense against the team’s $1.5M in personnel costs. This xed pricing provides cost predictability valuable for budgeting purposes, though organizations with highly variable development activity may pay for unused capacity.
Productivity improvement estimation requires controlled measurement comparing feature implementation time with and without AI assistance. Published research indicates productivity gains ranging from 25-55% depending on task characteristics, with greatest improvements for boilerplate code generation, test writing, and documentation creation. Applying conservative 30% productivity estimate to a 10-person engineering team yields effective capacity increase of 3 engineers, valued at approximately $450,000 annually. This productivity gain substantially exceeds tool costs, generating attractive ROI even with signicant implementation overhead and learning curves.
Opportunity cost considerations account for features delayed or not implemented due to capacity constraints. SaaS companies and startups in competitive markets face revenue impact from delayed feature launches, making productivity tools valuable even without reducing engineering headcount. The ability to implement
features weeks or months earlier than without AI assistance generates competitive advantages and revenue acceleration difficult to quantify precisely but potentially exceeding direct productivity measurements.
Quality cost implications require balanced assessment. AI coding tools reduce time spent on mechanical coding tasks but may introduce bugs requiring debugging eort, security vulnerabilities demanding remediation, and technical debt necessitating future refactoring. Organizations with strong code review processes and comprehensive test suites mitigate these quality risks, while those with weak quality gates potentially experience negative ROI through downstream quality costs exceeding upfront productivity gains.
Making the Selection: Decision Framework
Organizations evaluating Claude Code vs Codex should apply decision frameworks accounting for team composition, project characteristics, existing tooling, and organizational constraints rather than selecting based on benchmark performance or feature comparisons divorced from operational context.
For startups with small teams and rapid iteration requirements: Claude Code’s conversational interface and autonomous feature implementation provide maximum velocity with minimal process overhead. The ability to specify features in natural language and receive complete implementations suits fast-paced startup environments where implementation speed outweighs comprehensive testing and documentation. Startups should implement lightweight code review ensuring AI-generated implementations meet security and functional requirements before deployment.
For development agencies managing diverse client portfolios: Codex integration with GitHub Copilot provides consistent interface across varied technology stacks and client projects. The in-editor experience reduces context switching overhead when developers move between client engagements, while broad language support ensures value across the agency’s project portfolio. Agencies should establish client communication frameworks addressing AI tool usage disclosure and intellectual property considerations.
For SaaS development teams balancing feature development and maintenance: Tool selection depends on whether teams prioritize new feature velocity (favoring Claude Code) or integration with established workows (favoring Codex). SaaS teams with comprehensive test coverage and strong code review practices realize value from either platform, while those with weaker quality processes should prioritize tools encouraging human oversight. Technical debt remediation initiatives benefit particularly from Claude Code’s extended context and refactoring capabilities.
For enterprise engineering organizations: Codex’s AWS deployment option and ne-tuning capabilities address data sovereignty and compliance requirements that Claude Code’s public API access cannot satisfy.
Enterprises should evaluate whether data classication policies permit external code transmission, whether internal frameworks justify fine-tuning investment, and whether procurement processes favor OpenAI’s enterprise sales infrastructure. Security and compliance teams must review AI tool usage against regulatory requirements and establish appropriate governance frameworks
For solo developers and freelancers: Cost sensitivity and workflow simplicity favor Codex through GitHub Copilot’s fixed monthly pricing and familiar IDE integration. Solo developers benet from avoiding Claude Code’s terminal-based workflow requiring context switches from primary development environment, while GitHub Copilot’s predictable costs prevent budget surprises from variable usage patterns.
Organizations can implement pilot programs deploying both tools to subset teams, measuring productivity impacts, gathering developer feedback, and assessing workow integration before organization-wide adoption. Pilot programs should span sucient duration (8-12 weeks) allowing developers to develop prociency and workows adapting to AI assistance patterns rather than evaluating based on initial unfamiliarity.
Future Trajectory: Where AI Coding Is Heading
The AI coding landscape continues rapid evolution with substantial capabilities improvements expected through 2026 and beyond. Understanding trajectory helps organizations make tool selections accounting for future developments rather than optimizing solely for current capabilities that may become irrelevant within 12-18 months.
Model capabilities will continue improving through larger training datasets, improved architectures, and finetuning on high-quality code repositories. The performance gap between AI and human expert programmers on standardized benchmarks will continue narrowing, with AI systems potentially achieving human-level performance on complex algorithmic problems by late 2026 or early 2027. This capability progression suggests current tool limitations around complex problem-solving and architectural decisions will diminish, increasing the scope of development tasks suitable for AI implementation.
Multi-modal capabilities incorporating visual design mockups, database schemas, and system architecture diagrams will enable AI coding tools to implement complete features from heterogeneous specications rather than text-only descriptions. Developers will show UI mockups to AI systems and receive frontend implementations matching designs, or provide database schemas and business logic descriptions receiving complete backend implementations. These multi-modal capabilities reduce the specication eort required from developers, further accelerating development cycles.
Personalization and learning from individual developer or team patterns will improve suggestion relevance and reduce acceptance friction. AI coding tools will learn organizational coding standards, architectural preferences, and domain-specic patterns through observation of code review feedback and implementation modications, adapting outputs to match team conventions without explicit ne-tuning. This personalization makes AI assistance increasingly valuable over time as systems learn team-specic patterns.
Debugging and error explanation capabilities will extend AI assistance beyond initial code generation into the full development lifecycle. Developers will provide error messages and stack traces to AI systems receiving explanation of root causes and suggested fixes, reducing debugging time for obscure errors or unfamiliar codebases. This debugging assistance proves particularly valuable for junior developers learning new technologies or senior developers working with unfamiliar legacy systems.
Automated testing will evolve beyond simple unit test generation to comprehensive test suites including integration tests, end-to-end tests, and property-based tests providing stronger correctness guarantees. AI systems will analyze implementations, identify edge cases and potential failure modes, and generate test scenarios ensuring robust validation coverage. This testing automation addresses current limitations where AIgenerated code lacks comprehensive testing, reducing the human effort required to validate AI implementations.
The organizational implications of AI coding advancement extend beyond individual developer productivity to potential engineering team structure changes. Teams may evolve toward smaller senior engineer groups orchestrating AI coding agents rather than large teams of mixed-experience developers writing code manually. This structural shift creates workforce implications organizations should anticipate, including changing hiring criteria, modied career progression paths, and different skill emphasis in engineering education.
Conclusion: Context-Driven Tool Selection
The choice between Claude Code and Codex reflects organizational context more than inherent tool superiority, as each platform optimizes for different development workows, team structures, and operational requirements. Startups prioritizing velocity benefit from Claude Code’s autonomous feature implementation, while enterprises requiring data sovereignty and fine-tuning capabilities select Codex deployed on AWS infrastructure. Development agencies value Codex’s consistent IDE integration across diverse projects, while SaaS teams choose based on whether conversational iteration or established workow integration better fits their development processes.
AI coding tools represent the most significant developer productivity advancement since integrated development environments, but realizing potential benefits requires workow adaptation, governance frameworks, and quality processes accounting for AI-generated code characteristics. Organizations implementing AI coding tools as simple drop-in replacements for human developers without process changes encounter quality issues and security vulnerabilities that undermine productivity gains. Successful adoption balances AI autonomy against human oversight, establishing review processes appropriate for organizational risk tolerance and code criticality.
The rapid capability improvement trajectory suggests current tool limitations around complex problem-solving, architectural coherence, and security awareness will diminish over coming years. Organizations should select tools based on current capabilities while monitoring development roadmaps and capability improvements that may shift optimal tool selection as platforms evolve. Flexibility to switch between platforms or adopt new entrants as capabilities and organizational requirements change prevents premature lock-in to tools becoming suboptimal as technology and organizational context evolve.
For organizations building web applications or developing complex software systems, AI coding agents represent transformative productivity tools when implemented thoughtfully with appropriate governance. The decision between Claude Code and Codex should emerge from systematic evaluation of development workflows, team technical prociency, data governance requirements, and alignment with existing toolchains rather than benchmark performance or feature lists divorced from operational reality


